
por Fernando Jiménez | Sep 23, 2021 | Agile, Digitalización, Tecnología
Arquitecturas limpias y DDD, un recorrido práctico. Parte 1 Arquitectura | DDD | Desarrollo Cuando se aborda un nuevo proyecto de software en el que intervienen múltiples stakeholders, se implican diversos componentes o sistemas terceros, o trata de implementar...

por José Antonio | Jun 21, 2021 | Digitalización, Sin categoría, Sixphere
Digitalizar en plano secuencia Transformación digital No debe haber miedo en afirmar, simplemente por ser en apariencia un concepto opuesto al frío tecnológico, que la digitalización trata de emociones. Tras cada decisión de optimización, tras cada idea de mejora o...

por Maribel Sánchez | May 25, 2021 | Digitalización, Sin categoría, Sixphere
El papel de la protección de datos en tiempos de teletrabajo Privacidad | Protección de datos | Seguridad | Teletrabajo El teletrabajo y la protección de datos en los tiempos que corren deben ir de la mano. Desde la incorporación masiva del teletrabajo en nuestras...
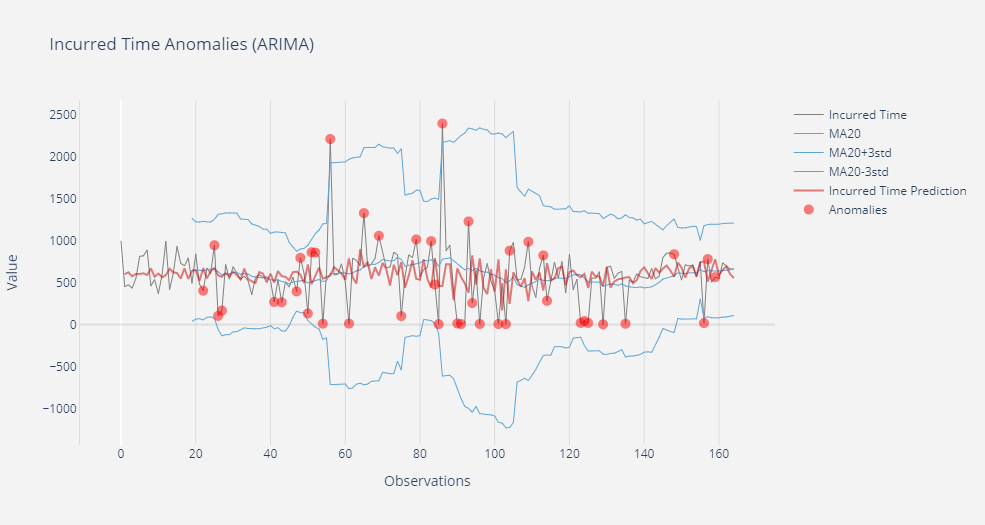
por Jesús María Jurado | Abr 19, 2021 | Datos, Digitalización, Sin categoría
Big Data, anomalías y predicción: análisis de una serie temporal Big Data | Machine Learning El tiempo de fabricación de un elemento en una línea de producción es, debido a la naturaleza propia del proceso, un valor que no debe variar demasiado en el tiempo. Sólo debe...

por José Antonio | Abr 1, 2021 | Datos, Digitalización, Sin categoría
Tres formas de explotar datos en tu proceso de digitalización Big Data | Industria 4.0 | Transformación digital El auge de la transformación digital de procesos productivos y de negocio, así como la implantación intensiva de sistemas de información, han abierto una...

por Jesús Serrano | Mar 11, 2021 | Datos, Digitalización, Sin categoría
Big Data y su papel en la fábrica del futuro Big Data qué es y cómo funciona El término Big Data lleva ya un tiempo copando buena parte de la información tecnológica. Un concepto que ha ido tomando importancia debido a que cada vez se generan más datos, a mayor...